Chapter 56、Error analysis by parts and comparison to human-level performance
组件错误分析和与人类水平的对比
在学习算法上执行错误分析就像用数据科学来分析ML系统的错误,目的是获得下一步该怎么做的见解。最基本的,组件错误分析告诉我们哪个组件的性能最值得努力提升。
假如你有消费者在一个网站上买东西的数据集。数据科学家可能有很多不同的方法去分析该数据。她可能会就网站是否应该提高价格、关于通过不同营销活动获得消费者的终身价值等等得出很多不同的结论。没有一种“正确”的方法去分析数据集,并且可以得出很多可能有用的见解。类似的,没有一种“正确”的方法去执行错误分析。通过这些章节,你学到了很多用于得到关于ML系统有用见解的最常见的设计模式,但你也可以自由尝试其他错误分析方法。
让我们回到自动驾驶应用,汽车检测算法输出附近汽车的位置(也可能是速度),行人检测算法输出附近行人的位置,这两个输出最终用于为当前汽车规划路径。
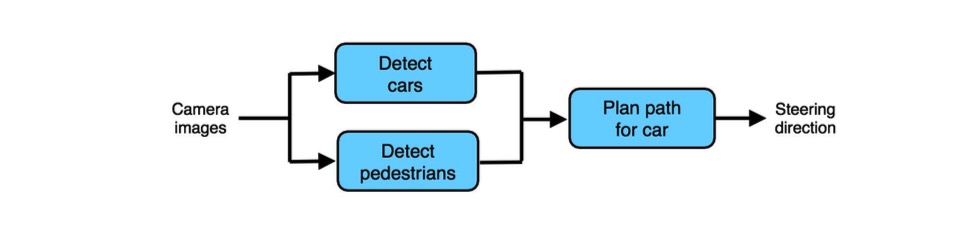
为了调试这个流水线,而不是严格遵循前一章节看到的过程,你可以更多非正式地询问:
- 汽车检测组件在检测汽车上和人类水平相比差多远?
- 检测行人组件和人类水平相比差多远?
- 系统的整体表现和人类水平相比差多远?这里人类水平表现假定为人类必须只根据前两个组件的输出(而不是方位摄像机图像)为汽车规划路线。换句话说,当人只路线规划组件的性能和人相比如何?
如果你发现其中一个组件远不及人类水平,现在你有一个很好的案例,专注于提高该组件的性能。
当我们尝试自动化一些人类可以做的事情时,很多错误分析过程表现的最好,因此可以对人类水平的性能进行基准测试。我们前面的大部分样例都有该隐含假设。如果你正在构建一个ML系统,其最终输出或者某些中间组件正在做一些甚至人类都不能做好的工作,那么这些步骤中的一些将不凑效。
这是解决人类可解决问题的另一个优势——你有更强大的错误分析工具,因此你可以更有效地优先考虑团队的工作。