Chapter 39、Weighting data
加权数据
假设你有20w来自互联网的图片和5000来自你的移动app用户的图片。这些数据的大小比例是40:1。从理论上来说,只要你构建一个大的神经网络并在这所有205000张图片上训练足够长的时间,对于我们试图让算法在互联网图片和移动图片上做的更好来说并没有什么坏处。
但是实践上来说,相比移动app图片而言,其40倍的互联网图可能意味着相比只训练5000张图片,需要花费40倍(或更多)的计算资源来对二者进行建模。
如果你没有庞大的计算资源,你可以给互联网图片一个较低的权重作为妥协。
例如,假设你的优化目标是平方差(对于分类任务,这不是一个好的选择,但它会简化我们的解释)。因此,学习算法试图去优化:
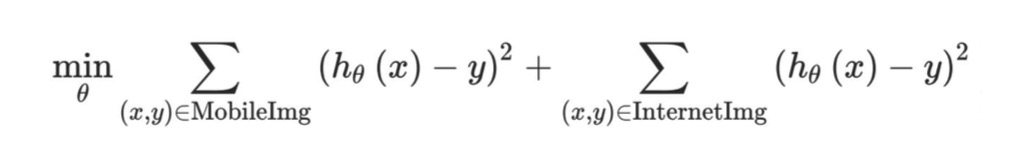
上面的第一个和是5000张移动图片,第二个和是2W张互联网图片。你可以改为使用额外的参数 $\beta$ 进行优化:
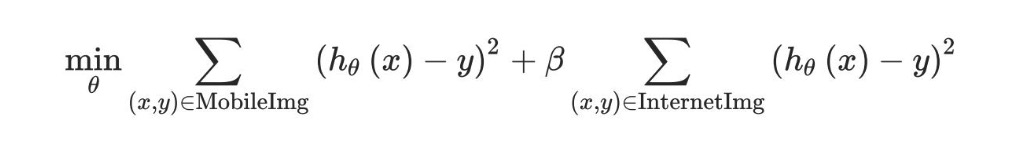
如果你设置 $\beta = 1/40$ ,算法会给5000移动图片和20W互联网图片相同的权重。你也可以设置参数 $\beta$ 为其他值,或者通过调整开发集。
通过将减少额外的互联网图降低权重,你不必构建一个大的神经网络来确保算法在两种类型的任务上都做的很好。只有当你怀疑附加数据(互联网图片)的分布与开发/测试集非常不同时,或附加数据远大于来自相同分布的开发/测试集(移动图片),此时这类数据需要重新调整权重。