Chapter 41、Identifying Bias, Variance, and Data Mismatch Errors
识别偏差、方差和数据不匹配误差
假设人在猫检测任务上可以达到几乎完美的表现(~0%错误),因此最优错误率大约是0%。假设你有:
- 训练集上1%的错误
- 训练开发集上5%的错误
- 开发集上5%的错误
这告诉你什么?这里,你了解到有高方差。先前描述的减少方差的方法应该可以使你取得进步。
现在,假设你的算法取得:
训练集上10%的错误
训练开发集上11%的错误
开发集上12%的错误
这告诉你在训练集上有高可避免偏差。即算法在训练集上做的很差。减少偏差的方法应该有所帮助。
上面的两个例子,算法只遭受有高可避免偏差或高方差。算法可能遭受任何子集的高可避免偏差,高方差和数据不匹配。例如:
- 训练集上10%的错误
- 训练开发集上11%的错误
- 开发集上20%的错误
算法遭受高可避免偏差和数据不匹配。然而,并没有在训练集分布上遭受高方差。
通过将不同类型错误绘制为表上的条目,可能更容易理解它们之间如何相互联系:
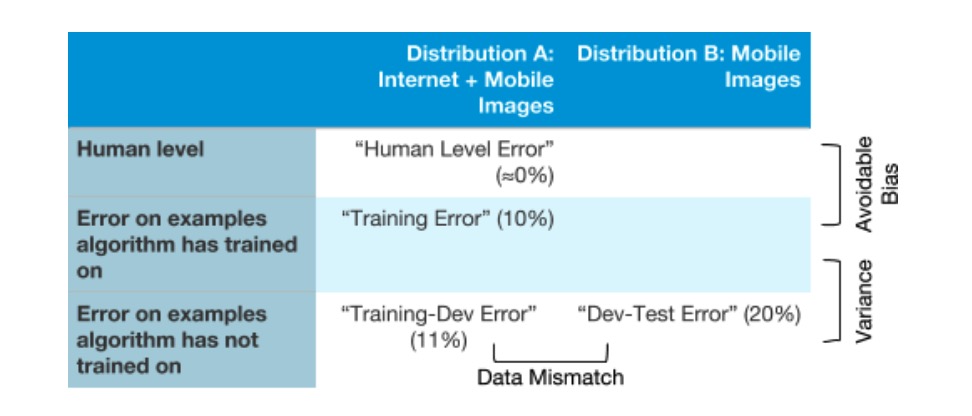
继续猫图检测器的例子,你可以看到在x轴上有两种不同数据分布。在y轴上,有三种错误类型:人水平错误,在算法已经训练过样例上的错误,在算法没有训练过样例上的错误。我们可以填写上一章节中已经确定的不同错误类型。
如果你愿意,你也可以填写表格中剩下的两个框:通过让人来标注移动猫图数据并测量他们的错误率,将其填入右上角的框中(在移动图片上的人水平表现)。通过将移动猫图(分布B)中的一小部分放入训练集中,以至于神经网络也可以学习到它,将其填入下一个框中。然后在数据子集上测量学习模型的错误。填入这两条附加条目有时可以提供额外的洞察力,关于算法在两种不同分布(分布A和B)的数据上的工作。
通过理解哪种类型的错误算法遭受的最多,你将更好的决定是否专注在减少偏差、减少方差还是减少数据不匹配。