Chapter 55、General case of error attribution
错误归因的一般情况
以下是错误归因的一般步骤。假设流水线有三个步骤A、B和C,A直接输入给B,B直接输入给C。

对每个系统在开发集上所犯的错误:
- 尝试人为修改A的输出为“完美”输出(例如,猫的“完美”回归框),然后在此输出上运行流水线B和C。如果算法现在给出正确的输出,那表明如果只有A提供更好的输出,整体的算法输出才是正确的;因此,你可以将错误归因于组件A。否者,进行第二步。
- 尝试人为修改B的输出为“完美”输出,如果算法现在给出正确的输出,那么将错误归因于组件B。否者,进行第三步。
- 将错误归因于组件C。
让我们看一个更复杂的例子:
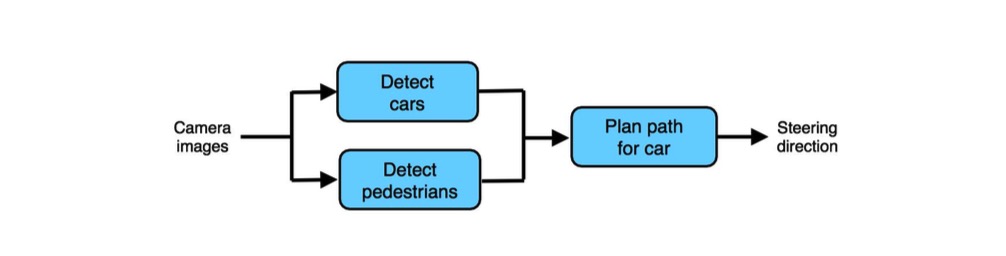
自动驾驶汽车使用该流水线。你如何按步执行错误分析来决定应该专注于哪个组件?
你可以将这三个组件按如下方式映射为A,B,C:
- A: Detect cars
- B: Detect pedestrians
- C: Plan path for car
按照上述程序,假设你在一个封闭的轨道上测试你的汽车,发现一个案例,汽车选择了比熟练的司机更加刺耳的转向方向。在自动驾驶的世界中,该案例通常被称为场景。然后你可以:
- 尝试人为修改A(检测汽车)的输出为“完美”输出(例如,人为介入并告诉它其他车的位置)。和往常一样运行剩下的流水线B、C,但允许C(路径规划)使用现在A的完美输出。如果算法现在为汽车规划了一条更好的路径,那表明,如果只有A提供更好的输出,整体算法的输出才会更好;因此,你可以将错误归因于组件A。否则,继续第2步。
- 尝试人为修改B(行人检测)的输出为“完美”输出。如果算法现在给出了正确的输出,那么将错误归因于组件B。否则,继续第3步。
- 将错误归因于组件C。
ML流水线的组件应该按照DAG(有向无环图)来排序,这意味着你可以使用某种固定的从左到右的顺序来计算它们,并且后面的组件应该仅依赖于前面组件的输出。只要组件到A->B->C顺序的映射遵循DAG排序,那么误差分析就没问题。如果你交换A和B,得到的结果可能略有不同:
- A: Detect pedestrians (was previously Detect cars)
- B: Detect cars (was previously Detect pedestrians)
- C: Plan path for car
但是该结果分析仍然有效,并可以很好的指导你该注意哪里。