Chapter 26、Error analysis on the training set
训练集上的误差分析
你的算法必须在训练集上表现很好,然后才能期望它在开发/测试集上表现很好。
除了之前描述的处理高偏差的方法之外,我有时也对训练数据进行错误分析,遵循类似于在 Eyeball 开发集上错误分析的规则。如果你的算法存在高偏差,也就是说,不能很好的适应训练集,那这可能是有用的。
例如,假设你在为一个app构建语音识别系统,从志愿者那里收集了音频剪辑作为训练集。如果系统在训练集上做的并不好,你可以考虑听一下算法表现很差的 ~100个样本,在这些样本上算法在理解训练集错误的主要类别方面做的很差。和开发集错误分析类似,你可以统计不同类别的错误:
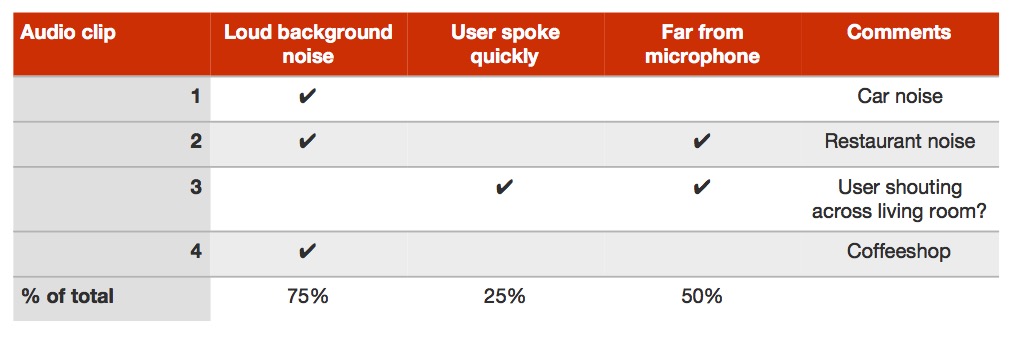
在这个例子中,你可能会意识到算法在处理有很多背景噪声的训练样本时会特别艰难。因此,你可以专注于使得算法能更好的适应有背景噪声训练样本的方法。
提供你的学习算法相同的输入音频,你也可以再次确认人是否可能转录这些音频剪辑。如果有太多的背景噪声以至于没人可以听出说了什么,那就没有理由去期望任何一个算法能正确识别这些话。我们将在后一章中讨论将算法和人类表现水平相比较的益处。