Chapter 50、Choosing pipeline components: Data availability
选择流水线组件:数据可用性
当构建一个非端到端的流水线系统时,对于流水线的组件来说什么是最好的选择呢?如何设计流水线将极大影响整个系统的性能。一个重要的因素是你是否可以容易地收集数据来训练每个组件。
例如,考虑如这种自动驾驶架构:
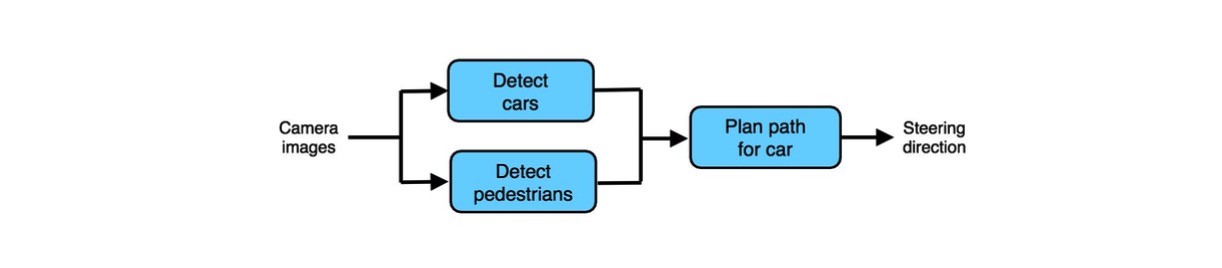
你可以使用机器学习来检测汽车和行人。而且,获取这些数据并不难:有很多计算机视觉数据集,它们有大量标注的汽车和行人。你也可以使用众包(例如亚马逊土耳其机器人)来获取更大的数据集。因此获取训练数据来构建一个汽车检测器和行人检测器相对容易。
相反,考虑一个纯粹的端到端方法:

为了训练该系统,我们需要一个大的(图片,转向方向)对数据集。收集该数据需要人们开车并记录他们的转向方向,这很耗时而且很贵。你需要一个特殊装备的车队,以及大量的驾驶来涵盖各种可能的情况。这使端到端系统很难训练。获取已标注汽车和行人的大型数据集要容易的多。
更为一般的说,如果有很多数据可用于训练一个流水线(例如汽车检测器或行人检测器)的“中间模块”,那么你可以考虑使用有多个阶段的流水线。这种架构可能更优,因为你可以使用所有可用的数据来训练中间模块。
直到更多端到端数据可用之前,我相信非端到端方法对自动驾驶更有希望:其架构更好匹配数据的可用性。