Chapter 51、Choosing pipeline components: Task simplicity
选择流水线组件:任务简单
除了数据可用性以外,当选择一个流水线的组件时,你还应该考虑第二个因素:各个组件解决的问题有多简单?你应该尝试选择易于构建和学习的流水线组件。但一个组件“易于”学习意味着什么?

考虑这些机器学习任务,按难度递增的顺序罗列如下:
- 分类图像是否过度曝光(如上例所示)
- 分类图像是在室内还是室外拍摄
- 分类图像是否包含猫
- 分类图像是否包含黑色和白色毛皮的猫
- 分类图像是否包含暹罗猫(特定品种的猫)
这些中的每一都是一个二进制图像分类任务:你必须输入一张图像,输出为0或1。但列表中较早的任务让一个神经网络来学习似乎太“更简单”。你将可以用更少的训练样本来学习更简单的任务。
机器学习没有很好的正式定义什么使任务变得容易或困难【1】。随着深度学习和多层神经网络的兴起,我们有时会说,如果一个任务可以以更少的计算步骤(对应于浅层神经网络)执行,那么该任务是“简单的”,如果一个任务需要更多计算步骤(需要更深的神经网络),那该任务是“困难的”。但这些都是非正式的定义。
如果你能够执行复杂的任务,并将其分解成简单的子任务,那么通过明确地编写子任务的步骤,你正在为算法提供先验知识,以帮助其更有效的学习任务。

假设你正在构建一个暹罗猫检测器。这是纯粹的端到端架构:

相比之下,你可以使用有两个步骤的流水线架构:

第一个步(猫检测器)检测图片中所有的猫。

第二步将每个检测出的猫(一次一个)的裁剪图像传入猫种类分类器,如果检测出的猫是暹罗猫,那么最终输出为1。
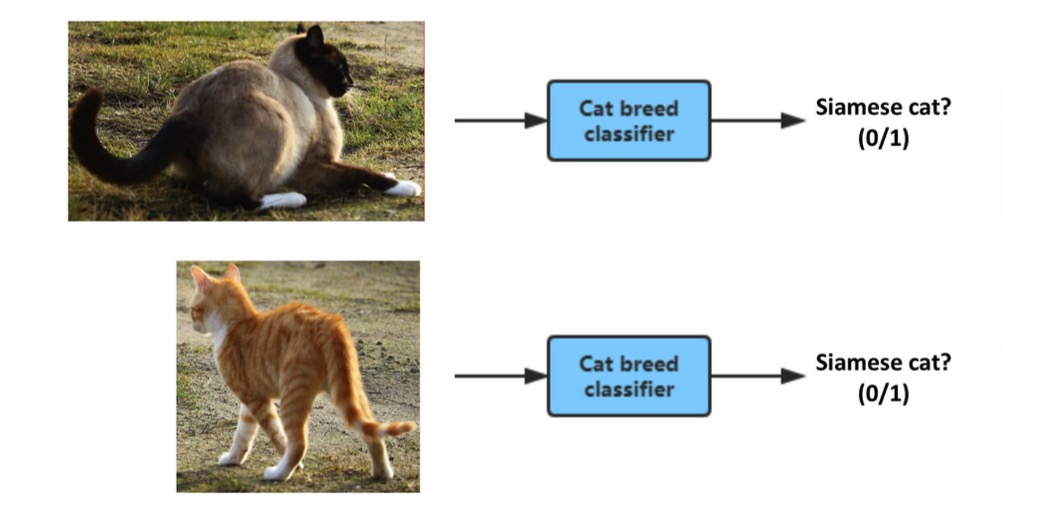
相比仅使用标签0/1训练一个纯粹的端到端分类器,流水线中两个组件的每一个(猫检测器和猫品种分类器)似乎更容易学习并且将需要更少的数据【2】。
作为最后一个例子,让我们再来看看自动驾驶流水线。
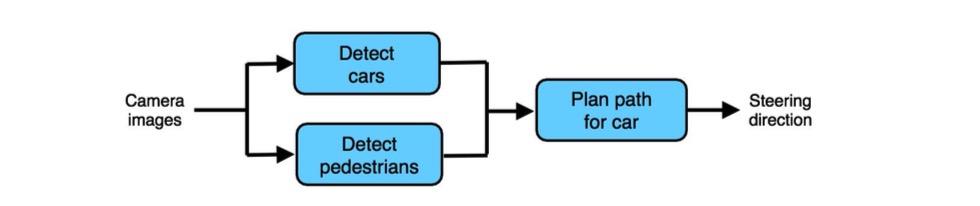
通过使用该流水线,你告诉算法驾驶有3个关键的步骤:(1)检测其他汽车,(2)检测行人,和(3)为你的车规划路线。此外,相对于纯粹的端到端学习方法,这些步骤中的每一个都是相对简单的功能(因此可以使用更少的数据学习)。
总之,在决定流水线中的组件应该是什么时,尝试构建一个流水线,其每个组件功能相对“简单”,因此可以只需从适量的数据中学习。
————————
【1】 信息理论具有“Kolmogorov复杂性”的概念,其表示学习函数的复杂性是可以产生该函数的最短计算机程序的长度。然而,这一理论概念在人工智能中几乎没有实际应用。可参见:https://en.wikipedia.org/wiki/Kolmogorov_complexity
【2】 如果您熟悉实际物体检测算法,您将认识到它们不仅仅学习0/1图像标签,而是使用作为训练数据一部分提供的边界框进行训练。对它们的讨论超出了本章的范围。如果您想了解有关此类算法的更多信息,请阅读Coursera上的深度学习专业(http://deeplearning.ai)。