Chapter 28、Diagnosing bias and variance: Learning curves
诊断偏差和方差:学习曲线
我们已经看过一些方法去估计有多少错误可归因于可避免的偏差和方差。我们是通过估计最优错误率,并计算算法的训练集和开发集错误来进行估计的。让我们讨论一个更具信息性的方法:绘制学习曲线。
学习曲线会根据训练样本的数量来绘制开发集错误。为了绘制它,你可以使用不同大小的训练集去运行算法。例如,如果你有1000个样本,你可以在100,200,300,…,1000个样本上单独训练算法副本。然后你就能画出开发集错误如何随着训练集大小而变化的曲线了。如下图所示:
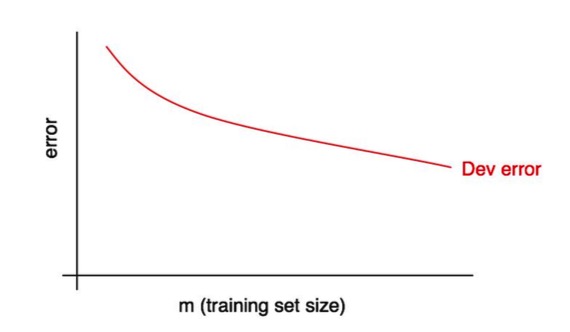
随着训练集大小的增加,开发集错误应该减少。
我们经常会有一些我们希望学习算法最终能达到的“期望错误率”。例如:
- 如果我们希望达到人类水平的表现,那么人类错误率可能就是“期望错误率”。
- 如果我们的学习算法为某些产品提供服务(如提供猫图),我们可能会直观的了解需什么样的水平才能给用户提供出色的体验。
- 如果你长期从事于一个重要应用,那么你可能会有直觉认为在下一个季度/年内能合理取得多大进展。
将期望的表现水平添加到你的学习曲线中:
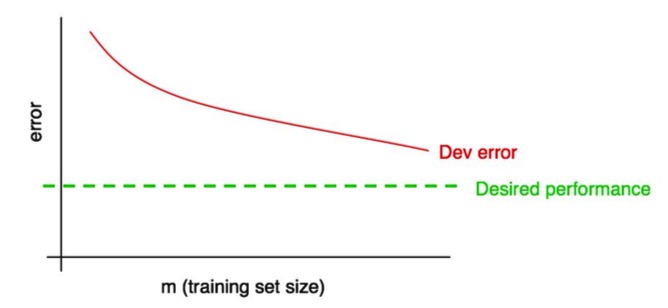
你可以直观的看到外推红色的“开发错误”曲线,以此来猜测通过添加更多的数据你能够多接近期望的性能水平。在上面的例子中,通过加倍训练集大小来达到期望的水平看似合理的。
但如果开发错误曲线趋于“稳定”(即变平),那么你可以立刻知道添加更多数据并不能达到你的目标:
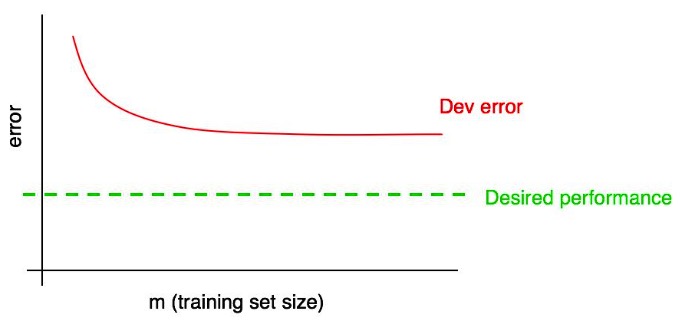
查看学习曲线可能会帮助你避免花费数月时间来收集两倍多的训练数据,只有意识到这并不管用。
这个过程的一个缺点是,如果你只关注开发错误曲线,如果有更多的数据,你很难推断和准确预测红色的曲线的走向。这里有一个附加的曲线能够帮助你去评估添加更多数据的影响:训练错误。