1. ceph简介
1.1. 架构
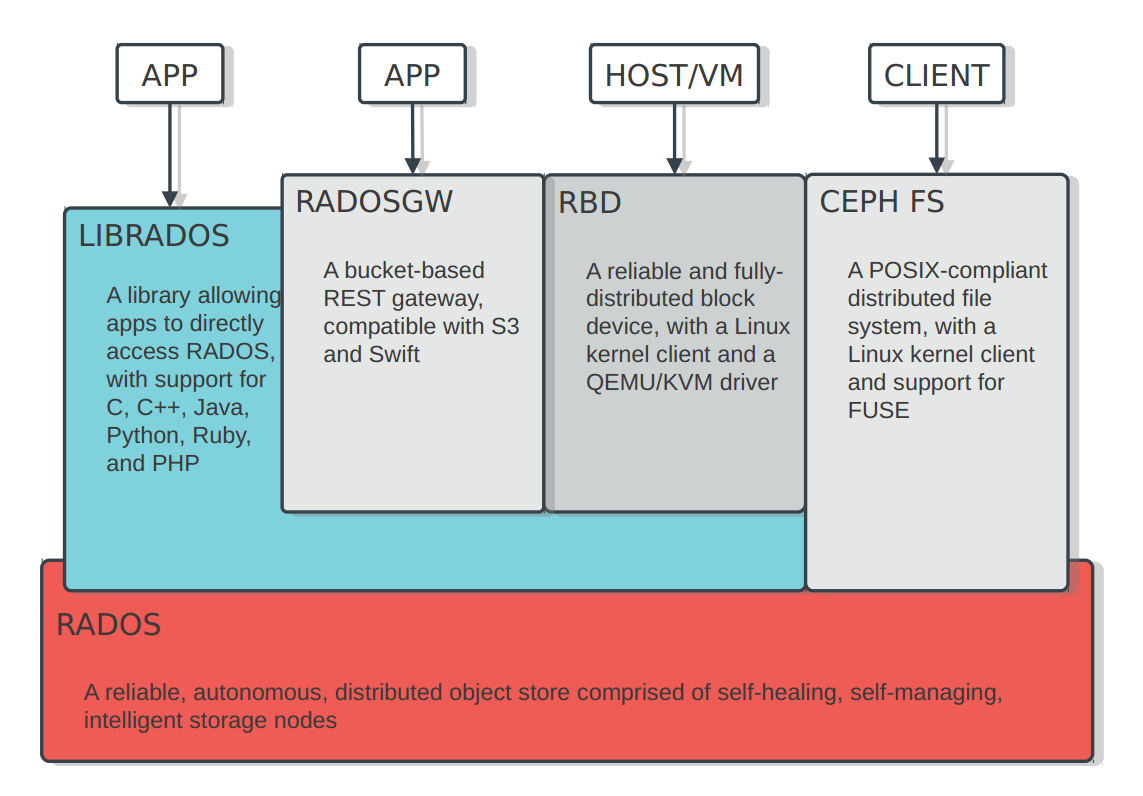
1.2. 组件
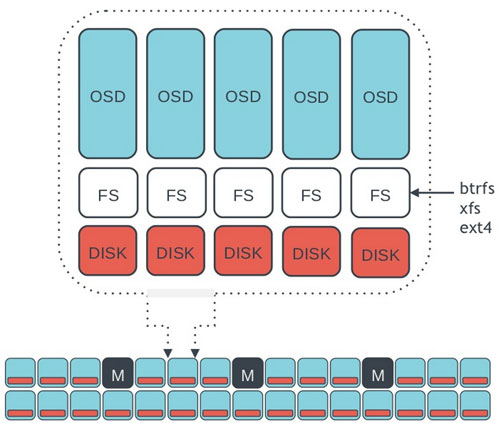
Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”。 RADOS由两个组件组成:
- OSD: Object Storage Device,提供存储资源。
- Monitor:维护整个Ceph集群的全局状态。
RADOS具有很强的扩展性和可编程性,Ceph基于RADOS开发了 Object Storage、Block Storage、FileSystem。Ceph另外两个组件是:
- MDS:用于保存CephFS的元数据。
- RADOS Gateway:对外提供REST接口,兼容S3和Swift的API。
1.3. 映射
Ceph的命名空间是 (Pool, Object),每个Object都会映射到一组OSD中(由这组OSD保存这个Object):
(Pool, Object) → (Pool, PG) → OSD set → Disk
Ceph中Pools的属性有:
- Object的副本数
- Placement Groups的数量
- 所使用的CRUSH Ruleset
在Ceph中,Object先映射到PG(Placement Group),再由PG映射到OSD set。每个Pool有多个PG,每个Object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD的个数由Pool 的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
数据映射(Data Placement)的方式决定了存储系统的性能和扩展性。(Pool, PG) → OSD set 的映射由四个因素决定:
- CRUSH算法:一种伪随机算法。
- OSD MAP:包含当前所有Pool的状态和所有OSD的状态。
- CRUSH MAP:包含当前磁盘、服务器、机架的层级结构。
- CRUSH Rules:数据映射的策略。这些策略可以灵活的设置object存放的区域。比如可以指定 pool1中所有objecst放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服 器上,第3个副本分布在机架4的服务器上。
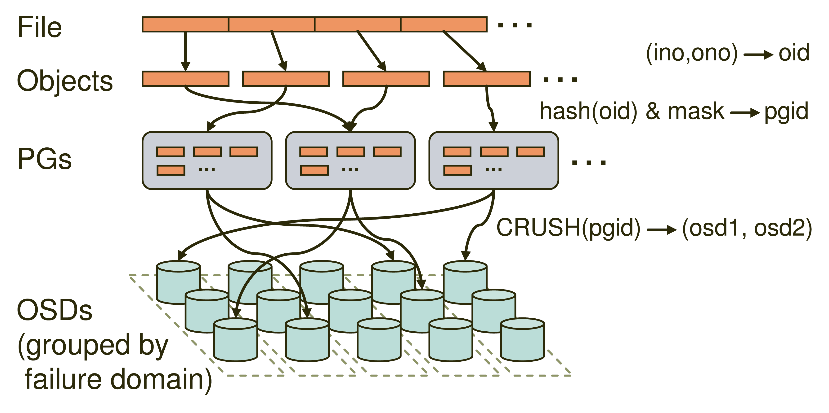
Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。伪代码如下所示:
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osds
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
这种数据映射的优点是:
- 把Object分成组,这降低了需要追踪和处理metadata的数量(在全局的层面上,我们不需要追踪和处理每个object的metadata和placement,只需要管理PG的metadata就可以了。PG的数量级远远低于object的数量级)。
- 增加PG的数量可以均衡每个OSD的负载,提高并行度。
- 分隔故障域,提高数据的可靠性。
1.4. RBD
在单机情况下,RBD的性能不如RAID10,这是为什么?我们可以通过三种方法找到原因:
- 阅读Ceph源码,查看I/O路径
- 使用blktrace查看I/O操作的执行
- 使用iostat观察硬盘的读写情况
RBD的I/O路径很长,要经过网络、文件系统、磁盘:
Librbd -> networking -> OSD -> FileSystem -> Disk
Client的每个写操作在OSD中要经过8种线程,写操作下发到OSD之后,会产生2~3个磁盘seek操作:
- 把写操作记录到OSD的Journal文件上(Journal是为了保证写操作的原子性)。
- 把写操作更新到Object对应的文件上。
- 把写操作记录到PG Log文件上。
我使用fio向RBD不断写入数据,然后使用iostat观察磁盘的读写情况。在1分钟之内,fio向RBD写入了3667 MB的数据,24块硬盘则被写入了16084 MB的数据,被读取了288 MB的数据。
向RBD写入1MB数据 = 向硬盘写入4.39MB数据 + 读取0.08MB数据
总结:
在单机情况下,RBD的性能不如传统的RAID10,这是因为RBD的I/O路径很复杂,导致效率很低。但是Ceph的优势在于它的扩展性,它的性能会随着磁盘数量线性增长,因此在多机的情况下,RBD的IOPS和吞吐率会高于单机的RAID10(不过性能会受限于网络的带宽)。
原文链接:http://way4ever.com/?p=425
2. 优缺点
2.1. 优点
- CEPH的特点是Crush+Rados,Crush可以实现把数据可控的分布在不同的故障域内,实现高可用的目的;
- 而Rados实现了集群机器增减后的数据自动重新平衡。
- 其接口支持广泛,对iSCSI/FC,openstack的QEMU和linux kernel的rbd都有支持,对块存储的高级特性如快照/克隆/扩减容都支持,基本上是开箱即用,非常方便。
2.2. 缺点
- 单独提供的云磁盘缺少QOS控制(openstack可以通过vm的设定控制iops);
- 由于journal的缘故,性能受限,显得平庸;(写路径过长:写log->写journal->写磁盘)
- 集群扩容缩容时会出发数据迁移,SATA-HDD下,2T的数据量会持续一天左右(按照磁盘预留20M/s供数据平衡计算,过多数据平衡会影响集群性能输出)。
- 另外,CEPH追求对象存储/块存储/文件存储的大一统,这让块存储构建于对象存储上,设计上多有折中,影响了性能发挥,参见ScaleIO与CEPH的性能对比 。
- ceph是乱序写
- ceph的每一个对象对应于磁盘上的一个文件,磁盘上小文件数据过多会影响文件系统的性能。
- OSD数量过多时,crush计算会对cpu产生严重开销
3. 性能调优
3.1. CPU加速
使用numa(Non-Uniform Memory Access)绑定cpu以提升性能
uma方法,cpu访问任意内存的代价是一样的,都需要经过总线进行存取;numa不同cpu访问本地内存是可不经过总线直接访问,以获得低延迟,跨numa-node访问的延迟较高。
对于ceph而言,每个ceph进程占用内存较少(4G左右),绑定ceph进程到指定的numa-node,进程将被调度到该node,这样内存访问总是在node内,降低了内存的访问延迟,从而提升性能。
3.2. 高可用高性能
1、高可用性
(1) 当节点或osd进程hang住时,减少ceph集群不可用的时间间隔。
(2) 数据恢复时,对磁盘带宽限速。[xsky]
(3) 数据恢复时,采用partial恢复,而不是整个对象,这对块存储的性能影响很大。[社区已经有人在做,收益确定,需要等待]
(4) 持续数据保护,支持三天内正点,1天内每小时,12小时内每秒的回滚操作。[有思路]
2、高性能
(1) librbd性能优化[xsky做过,合并物理机发往同一个osd的请求。]
(2) 对象存储小文件归档[考虑到bluestore的即将推出,这个优化意义不大,可以先测试目前的bluestore,观察性能,如果bluestore的性能不济,可作这个考虑]
3、其他
块设备的QOS。[社区中已经有dmclock的pr,暂时未生效。个人觉得可以在librbd处控制qos]
3.3. 对象存储
ceph之间的指标差别主要源于filestore引擎: 七牛ceph使用dm层的cache方案对元数据进行了缓存; 友商除了自己的缓存方案外,还使用了小文件归档的方式降低元数据读写负担。 在bluestore推出后,这些优化方案则不再适用。
目前ceph(K版本)的存储引擎是filestore(未来将是bluestore,对性能的提升很大), 将对象的管理委托给了文件系统(推荐xfs),海量小对象对xfs的元数据管理造成很大负担。 友商在filestore上做了小文件归档以提升性能。
ceph对称架构在加入新节点时会触发数据的重新平衡, 类似七牛公有云的海量场景无法掌控。
3.4. 块存储
七牛块存储目前基于ceph,支持iscsi/kernel rbd/nbd-rbd三种接口,已经完成了与openstack/k8s的对接。
内部应用上,为内部用户atlab提供存储服务。
因为社区版本还有很多功能待完善,因此目前做不到以块存储的方式出售,我们会根据市场的需求,选择部分特性优先开发,见下文。
私有云
块存储在私有云领域会采用QOS的方式来为每个卷分配存储资源,如IOPS或吞吐,防止某个卷消耗过多资源导致其他卷饥饿的情形。
其他参考资料:http://way4ever.com/?p=2989
3.5. 文件存储
基于ceph的文件存储方案有三种:cephfs,NFS over RBD,NFS over RGW
| 方案 | 说明 | 优缺点 |
|---|---|---|
| NFS over RGW [探索中] | 在对象存储网关之上支持NFS协议,打通了文件存储与对象存储。 | rgw将成为带宽瓶颈,容量无限制。 |
| NFS over RBD [DONE, 可试用] | 在ceph的块设备上搭建NFS-server,采用standby+keepalived实现高可用。 | 单个rbd设备支持容量有限且NFS-server是性能瓶颈。 |
| cephFS [DONE, 可试用] | ceph的mds组件在ceph集群上提供了posix兼容的分布式文件系统。 | MDS负责存储cephfs的元数据,其高可用采用standby模式,数据访问直达osd,性能扩展性非常好。 社区称从J版本开始稳定,但目前没听到生产环境的应用案例。 |
4. CRUSH
CRUSH算法,全称 Controlled Replication Under Scalable Hashing。它是一种伪随机的算法,在相同的环境下,它能够在层级结构的存储集群中有效的分布对象的副本。
CRUSH算法是Ceph对象存储的核心, 决定了每一个对象(Object)的存放位置。当需要存放一个Object时,只需要知道Object的id、集群架构图(cluster map)和存放策略(rule),就可以计算出应该存放在哪个OSD上。因此Ceph的元数据不需要包含位置信息,每个Client都可以自己计算出对应的OSD,大大减少了对元数据的请求。
CRUSH算法将集群架构图看作Buckets和Devices组成的树形结构,每个Bucket包含多个Device,Bucket也可以包含其它类型的Bucket。一共有四种类型的Buckte,使用四种定位算法。
crush算法:http://way4ever.com/?p=122
象有多少个副本,这些副本存储的限制条件(比如3个副本放在不同的机架中)。
CRUSH算出x到一组OSD集合(OSD是对象存储设备):
(osd0, osd1, osd2 … osdn) = CRUSH(x)
CRUSH利用多参数HASH函数,HASH函数中的参数包括x,使得从x到OSD集合是确定性的和独立的。CRUSH只使用了cluster map、placement rules、x。CRUSH是伪随机算法,相似输入的结果之间没有相关性,相同的输入得到的结果是确定的。
和一致性hash的区别:
CRUSH resembles consistent hashing. While consistent hashing would use a flat server list to hash onto, CRUSH utilizes a server node hierarchy (shelves, racks, rows) instead and enables the user to specify policies such as "Put replicas onto different shelves than the primary".
我自己的博客总结:http://xiaqunfeng.cc/2017/01/24/Crushmap%E5%AD%A6%E4%B9%A0/
5. RADOS
RADOS是使用CRUSH算法的分布式对象存储。由OSD和MON组成,OSD承担数据的存储、备份以及恢复,MON保证集群架构图与实际情况相符。RADOS的特点之一就是数据的备份、同步以及恢复等都由OSD自发的完成。
5.1. mon
RADOS中OSD独自管理数据的能力是建立在CRUSH算法上的, CRUSH算法又是建立在crushmap(包含OSD的数量、组织结构以及存储策略)上的。因此拥有一份最新的crushmap, 对OSD是至关重要的,否则OSD无法确定隶属同一个PG的OSDs,也就无法完成数据的备份、同步等操作。
RADOS中使用一个由MON组成的小集群来生成最新的crushmap。当增/减OSD、修改OSD组织结构、修改存放策略或者发现OSD失效时,更新请求被发送到MON集群, MON生成一份新的crushmap。同时MON集群也对外提供crushmap的访问服务,其它节点可以从MON集群中获取一份最新的crushmap。MON集群中采用Lease机制确保每个MON对外提供的crushmap的一致性,采用Paxos协议选举出一个Leader, 由Leader负责生成新的crushmap。
另外, OSD节点之间互相通信的时候会比较各自拥有的crushmap的epoch, 用最新的crushmap替换旧的crushmap。
当client要从OSD中读取Object时, 如果client中还没有crushmap: client首先从MON集群中读取一份最新的crushmap, 然后计算出存放该Object的PG对应的OSDs, 然后client与目标OSD比较各自的crushmap的epoch, 同步到最新的crushmap。如果client中已经有crushmap,在和OSD通信时,如果OSD的crushmap版本更新, 那么更新client的crushmap。如果client和OSD的crushmap版本一致了,但都不是最新的, 使用旧的crushmap计算出的OSD上可能没有存放要访问的Object, 导致操作失败, 这时候client从Mon集群读取最新的crushmap。
5.2. pg
存储Object时,Object首先通过哈希函数被映射到一个PG(placement group), 这个PG又被通过CRUSH算法映射到一组OSD,Object就被存放在PG对应的这组OSD中。
使用PG的好处:
- PG的数量远远小于Object的数量,可以通过技术手段使从PG到OSD映射开销小于从Object直接映射到OSD的开销。
- PG的数量大于OSD的数量,可以使OSD的负载更加均衡。
PG的数量不能太多,否则每个OSD上承担的PG数目太多,会使OSD疲于与PG内其他OSD通信,CEPH文档上推荐每个OSD承担50~100个PG。
6. metadata
Ceph将元数据的管理和数据的存储分离开了。RADOS是一个单纯的对象存储。文件路径、文件名称以及读写权限管理等元数据的管理由MDS集群(注意不是RADOS中的MON集群)进行管理。
得益于Crush算法,MDS集群不需要记录文件的实际存放位置,只需记录文件对应的inode number和stripe number就可以通过Crush算法计算出文件存放在哪些OSD上。
每个MDS的操作日志都被及时存放到RADOS中, MDS故障时, 可以根据日志文件进行恢复。
元数据按照目录的树状结构分派到MDS上, 然后在运行中根据元数据的使用热度,调整元数据的存储位置,既考虑到了对元数据请求的局部性特点,又实现了整个MDS集群负载的均衡。
例如A目录下的所有文件的元数据都存储在MDS0上, 当发现A目录的元数据请求非常频繁时, 将A目录的元数据复制一份到MDS1上, 分担MDS0的压力。如果A目录下的目录数特别多,而且更新操作频繁,那么以丢失局部性为代价,将A目录下的目录根据哈希结果分布到MDS集群中。