1. DHT
DHT(Distribute Hash Table,分布式哈希表)路由数据算法。一致性哈希基本解决了在P2P环境中最为关键的问题——如何在动态的网络拓扑中分布存储和路由。每个节点仅需维护少量相邻节点的信息,并且在节点加入/退出系统时,仅有相关的少量节点参与到拓扑的维护中。
FusionStorage中采用了DHT算法,每个存储节点负责存储一小部分数据,基于DHT实现整个系统数据的寻址和存储。
1.1. 原理
首先,求出每个服务器的hash值,将其配置到一个 0~2^n 的圆环上(n通常取32)
其次,用同样的方法求出待存储对象的主键 hash值,也将其配置到这个圆环上
再次,从数据映射到的位置开始顺时针查找,将数据分布到找到的第一个服务器节点上
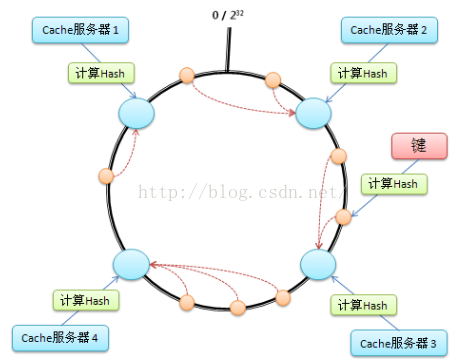
一致性hash的优点在于加入和删除节点时只会影响到在哈希还种相邻的节点,而对其他节点没有影响。
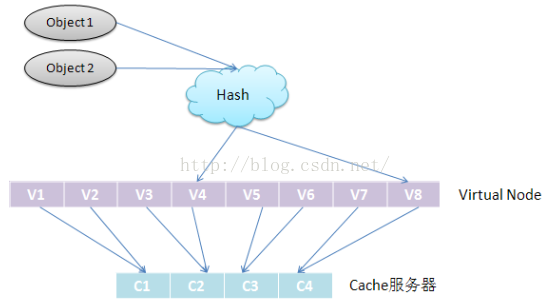
1.2. 虚拟节点
问题:在3和4之间增加节点5时,虽然只影响到原先分布到节点4的数据分布(重新分布到节点5),但当需要迁移的数据过多时,整个集群的负载不均衡。
想法:将需要迁移的数据分散到整个集群,每台服务器只需迁移 1/N 的数据量即可。这就引入了虚拟节点的概念。
考虑到节点的异构性,不同节点的处理能力差别可能很大,每个物理节点根据其性能的差异分配多个 token, 每个 token 对应一个“虚拟节点”,每个虚拟节点的处理能力基本相当,并随机分配在哈希空间中。存储时,数据安装哈希值落到某个虚拟节点负责的区域,然后被存储在该虚拟节点对应的物理节点中。
引入了“虚拟节点”后,映射关系发生了变化;【对象--->服务器】……>【对象--->虚拟节点---> 服务器】
查询对象所在服务器的映射关系如下图所示:
1.3. 特点
- 均衡性:数据能够尽可能分布到所有的节点中,这样可以使得所有节点负载均衡。
- 单调性:当有新节点加入系统中,系统会重新做数据分配,数据迁移仅涉及新增节点,现有节点上的数据不需要做很大调整。
原文来自我之前写的文章:分布式存储和一致性哈希
2. CAP
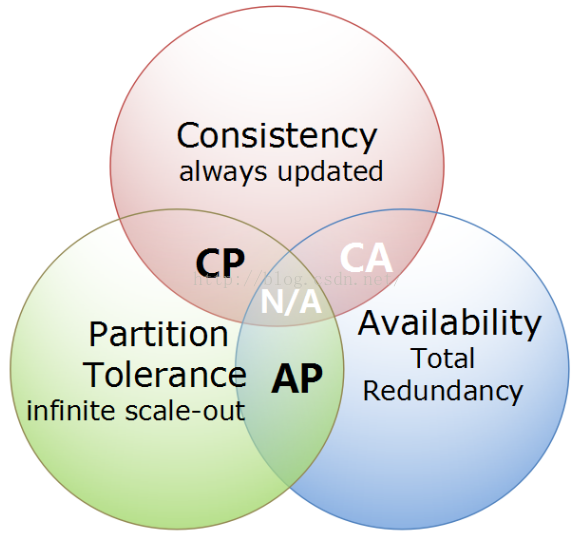
CAP理论,指的是在一个分布式系统中,不可能同时满足Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能满足其中的两项。
- 一致性:在分布式系统中数据往往存在多个副本,一致性描述的是这些副本中的数据在内容和组织上的一致。
- 可用性:可用性描述了系统对用户的服务能力,所谓可用是指在用户容忍的时间范围内返回用户期望的结果。
- 分区容错性:分布式系统通常由多个节点构成,由于网络是不可靠的,所以存在分布式集群中的节点因为网络通信故障导致被孤立成一个个小集群的可能性,即网络分区,分区容错性要求在出现网络分区时系统仍然能够对外提供满足一致性的可用服务。
传统对于 CAP 理论的理解认为在设计分布式系统时必须满足 P,然后在 C 和 A 之间进行取舍,这是片面的,实际中网络出现分区的可能性还是比较小的,尤其是目前网络环境正在变得越来越好,甚至许多系统都拥有专线的支撑,所以在网络未出现分区时,还是应该兼顾 A 和 C;另外就是对于一致性、可用性,以及分区容错性三者在度量上也应该有一个评定范围,最简单的以可用性来说,当有多少占比请求出现响应超时才可以被认为是不满足可用性,而不是一出现超时就认为是不可用的;最后我们需要考虑的一点就是分布式系统一般都是一个比较大且复杂的系统,我们应该从更小的粒度上对各个子系统进行评估和设计,而不是简单的从整体上武断决策。
3. ACID
原子性(Atomicity)、一致性(Consistency)、隔离性(isolation)、永久性(durability)
- Atomicity(原子性):一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
- Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器)、级联回滚等。
- Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
4. BASE
BASE理论是指,Basically Available(基本可用)、Soft-state( 软状态/柔性事务)、Eventual Consistency(最终一致性)。是基于CAP定理演化而来,是对CAP中一致性和可用性权衡的结果。
核心思想:即使无法做到强一致性,但每个业务根据自身的特点,采用适当的方式来使系统达到最终一致性。
1、基本可用:
指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。但不等价于不可用。比如:搜索引擎0.5秒返回查询结果,但由于故障,2秒响应查询结果;网页访问过大时,部分用户提供降级服务,等。
2、软状态:
软状态是指允许系统存在中间状态,并且该中间状态不会影响系统整体可用性。即允许系统在不同节点间副本同步的时候存在延时。
3、最终一致性:
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态,不需要实时保证系统数据的强一致性。最终一致性是弱一致性的一种特殊情况。
BASE理论面向的是大型高可用可扩展的分布式系统,通过牺牲强一致性来获得可用性。ACID是传统数据库常用的概念设计,追求强一致性模型。
5. 网络分区
俗称“脑裂”。当网络发生异常情况,导致分布式系统中部分节点之间的网络延时不断变大,最终导致组成分布式系统的所有节点中,只有部分节点之间能够进行正常通信,而另一些节点则不能。
当网络分区出现时,分布式系统会出现局部小集群。
6. 三态
分布式系统的每一次请求和响应包含:成功,失败,超时三种状态。
7. EC
纠删码(erasure coding,EC)是一种数据保护方法,它将数据分割成片段,把冗余数据块扩展、编码,并将其存储在不同的位置,比如磁盘、存储节点或者其它地理位置。
副本策略和纠删码是存储领域常见的两种数据冗余技术。相比于副本策略,纠删码具有更高的磁盘利用率。
纠删码技术主要是通过纠删码算法将原始的数据进行编码得到冗余,并将数据和冗余一并存储起来,以达到容错的目的。其基本思想是将n块原始的数据元素通过一定的计算,得到m块冗余元素(校验块)。对于这n+m块的元素,当其中任意的m块元素出错(包括原始数据和冗余数据)时,均可以通过对应的重构算法恢复出原来的n块数据。生成校验的过程被成为编码(encoding),恢复丢失数据块的过程被称为解码(decoding)。
7.1. 对比三副本
纠删码相对于之前多副本(以三副本为例)的区别:
- 存储空间降低 :原来3副本需要3倍空间存储一份数据,纠删码只需要n/(n+m)倍空间存储一份数据。EC冗余度低、磁盘利用率高。
- 可靠性:3副本允许坏的副本数:2/3; 纠删码允许坏的副本数:m/(n+m)。三副本可靠性更高。
EC算法的额外负担:
- 计算量(只要有一个坏盘就得通过网络读出n倍的数据并重新计算)
- 数倍的网络负载
7.2. 写请求
对齐写
计算校验,拆分请求,发往各节点
非对齐写
先读出未对齐的stripe,和要写的数据一起计算校验,再拆分成多个请求,发往各个节点进行处理
关于sheepdog的ec分析:http://www.sysnote.org/2014/05/01/sheepdog-erasure-code/