1. Leveldb
1.1. 简介
LevelDB是Google开源的一套Key-Value持久存储引擎,IO的处理策略上可以看做BigTable的单机版(tablet)。其特点是读写性能很高,尤其是写性能比读性能还高。
leveldb是一个写性能十分优秀的存储引擎,是典型的LSM树(Log Structured-Merge Tree)实现。LSM树的核心思想就是放弃部分读的性能,换取最大的写入能力。、
LSM树写性能极高的原理,简单地来说就是尽量减少随机写的次数。对于每次写入操作,并不是直接将最新的数据驻留在磁盘中,而是将其拆分成(1)一次日志文件的顺序写(2)一次内存中的数据插入。leveldb正是实践了这种思想,将数据首先更新在内存中,当内存中的数据达到一定的阈值,将这部分数据真正刷新到磁盘文件中,因而获得了极高的写性能(顺序写60MB/s, 随机写45MB/s)。
1.2. 整体架构
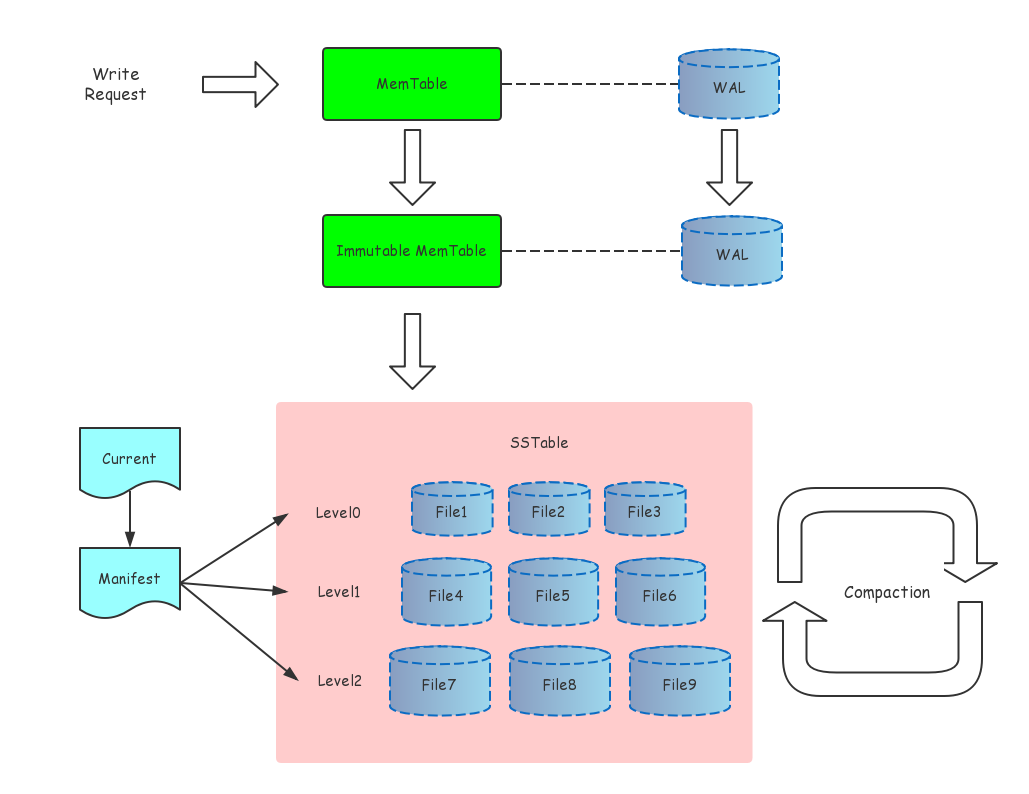
LevelDB 的静态结构主要由六个部分组成:
- MemTable:数据库存储的内存数据结构。具体实现是 SkipList。 接受用户的读写请求,新的数据修改会首先在这里写入。
- Immutable MemTable:待落盘的数据库内存结构。当 MemTable 的大小达到设定的阈值时,会变成 Immutable MemTable,只接受读操作,不再接受写操作,后续由后台线程 Flush 到磁盘上。
- SST Files:Sorted String Table Files,磁盘数据存储文件。分为 Level0 到 LevelN 多层,每一层包含多个 SST 文件,文件内数据有序。Level0 直接由 Immutable Memtable Flush 得到,其它每一层的数据由上一层进行 Compaction 得到。
- Manifest Files:leveldb元信息清单文件。Manifest 文件中记录 SST 文件在不同 Level 的分布,单个 SST 文件的最大、最小 key,以及其他一些 LevelDB 需要的元信息。由于 LevelDB 支持 snapshot,需要维护多版本,因此可能同时存在多个 Manifest 文件。
- Current File:当前正在使用的文件清单文件。由于 Manifest 文件可能存在多个,Current 记录的是当前的 Manifest 文件名。
- Log Files (WAL):用于防止 MemTable 丢数据的日志文件。
1.3. 写数据
- 先写入 MemTable。
- MemTable 的大小达到设定阈值的时候,转换成 Immutable MemTable。
- Immutable Table 由后台线程异步 Flush 到磁盘上,成为 Level0 上的一个 sst 文件。
- 在某些条件下,会触发后台线程对 Level0 ~ LevelN 的文件进行 Compaction。
1.4. 读数据
- 读 MemTable,如果存在,返回。
- 读 Immutable MemTable,如果存在,返回。
- 按顺序读 Level0 ~ Leveln,如果存在,返回。
- 返回不存在。
2. 其他
其他架构图
参考资料:https://leveldb-handbook.readthedocs.io/zh/latest/basic.html#id2
3. Rocksdb
LevelDB本身是一个lib形式发布的存储引擎,业界不少企业或个人在基本库上做了不少改进或封装,如RocksDB、SSDB等,思想和应用都影响较广。
3.1. 架构
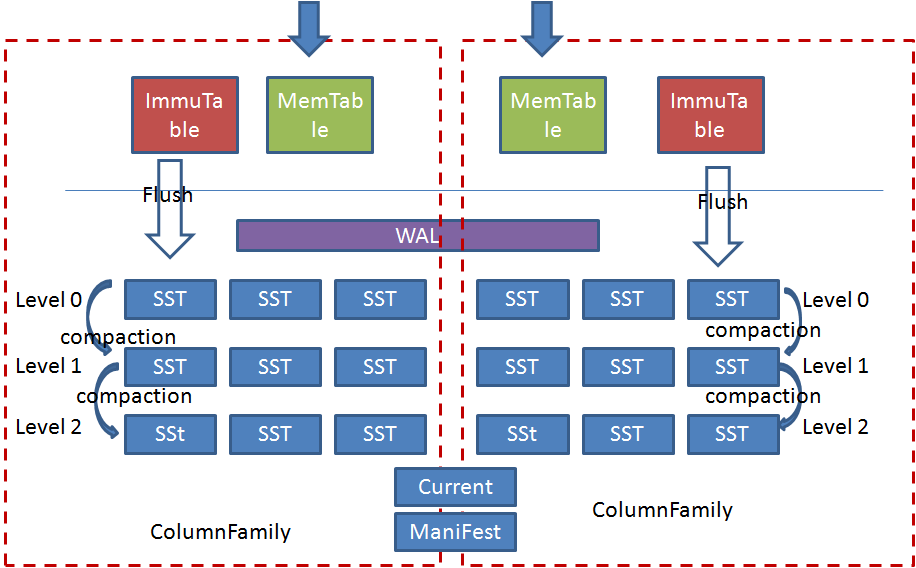
相比较leveldb的主要区别就是:
- Rocksdb中引入了ColumnFamily(列族, CF)的概念,所谓列族也就是一系列kv组成的数据集。所有的读写操作都需要先指定列族。
- 每个ColumnFamily有自己的Memtable, SST文件,所有ColumnFamily共享WAL、Current、Manifest文件。
3.2. 架构分析
整个系统的设计思路很好理解,这种设计的优势很明显,主要有以下几点:
- 所有的刷盘操作都采用append方式,这种方式对磁盘和SSD是相当有诱惑力的;
- 写操作写完WAL和Memtable就立即返回,写效率非常高。
- 由于最终的数据是存储在离散的SST中,SST文件的大小可以根据kv的大小自由配置,因此很适合做变长存储。
但是这种设计也带来了很多其他的问题:
- 为了支持批量和事务以及上电恢复操作,WAL是多个CF共享的,导致了WAL的单线程写 模式,不能充分发挥高速设备的性能优势(这是相对介质讲,相对B树等其他结构还是有优势);
- 读写操作都需要对Memtable进行互斥访问,在多线程并发写及读写混合的场景下容易形成瓶颈。
- 由于Level0层的文件是按照时间顺序刷盘的,而不是根据key的范围做划分,所以导致各个文件之间范围有重叠,再加上文件自上向下的合并,读的时候有可能需要查找level0层的多个文件及其他层的文件,这也造成了很大的读放大。尤其是当纯随机写入后,读几乎是要查询level0层的所有文件,导致了读操作的低效。
- 针对第三点问题,Rocksdb中依据level0层文件的个数来做前台写流控及后台合并触发,以此来平衡读写的性能。这又导致了性能抖动及不能发挥高速介质性能的问题。
- 合并流程难以控制,容易造成性能抖动及写放大。尤其是写放大问题,在笔者的使用过程中实际测试的写放大经常达到二十倍左右。这是不可接受的,当前我们也没有找到合适的解决办法,只是暂时采用大value分离存储的方式来将写放大尽量控制在小数据。
3.3. 场景
1、适用场景:
- 对写性能要求很高,同时有较大内存来缓存SST块以提供快速读的场景;
- SSD等对写放大比较敏感以及磁盘等对随机写比较敏感的场景;
- 需要变长kv存储的场景;
- 小规模元数据的存取;
2、不适合场景
- 大value的场景,需要做kv分离;
- 大规模数据的存取
4. 在大value场景下的一些问题
原文链接:http://idning.github.io/leveldb-rocksdb-on-large-value.html
Leveldb 2011年7月开源, 到现在有3年了, 原理上已经有很多文章介绍了, 我们就不多说.
其中最好的是淘宝那岩写的 leveldb 实现解析 和 TokuMX作者写的那个300页ppt: A Comparison of Fractal Trees toLog-Structured Merge (LSM) Trees (这个PPT 对读放大写放大分析很好, 值得再读一次)
最近基于LevelDB, RocksDB 做了一点东西, 我们的目标场景是存储平均50K大小的value, 遇到一些问题, 总结一下:
4.1. compaction不可控
当L0文件达到12个, 而compaction来不及的时候, 写入完全阻塞, 这个阻塞时间可能长达10s.
LevelDB实现上是L0达到4个时开始触发compaction, 8个时开始减慢写入, 12个时完全停止写入. 具体配置是写死的, 不过可以在编译时修改:
// Level-0 compaction is started when we hit this many files.
static const int kL0_CompactionTrigger = 4;
// Soft limit on number of level-0 files. We slow down writes at this point.
static const int kL0_SlowdownWritesTrigger = 8;
// Maximum number of level-0 files. We stop writes at this point.
static const int kL0_StopWritesTrigger = 12;
RocksDB这几个数字都可以通过参数设置, 相对来说好一些:
options.level0_slowdown_writes_trigger
options.level0_stop_writes_trigger
但是
- 一旦写入速度>compaction速度, 不论这几个阈值设置多大, L0都迟早会满的.
- 阈值调大会导致数据都堆积在L0, 而L0的每个文件key范围是重叠的, 意味着一次查询要到L0的每个文件中都查一下, 如果L0文件有100个的话,这大约就是100次IO, 读性能会急剧降低.实际上, RocksDB的
Universal Style就是把所有的数据都放在L0, 不再做compaction, 这样显然没有写放大了,但是读的速度就更慢了, 所以限制单个DB大小小于100G, 而且最好在内存.
4.2. 写放大
基准数据100G的情况下, 50K的value, 用200qps写入, 磁盘带宽达到100MB/s 以上.
真实写入数据大约只有50K*200=10MB/s, 但是磁盘上看到的写大约是10-20倍, 这些写都是compaction在写,
此时的性能瓶颈已经不是CPU或者是LevelDB代码层,而是磁盘带宽了, 所以这个性能很难提上去,
而且HDD和SSD在顺序写上性能差别不大, 所以换SSD后性能依然很差.
其它同学发现的issue:
- https://github.com/facebook/rocksdb/issues/210 提到的case, 12MB/s的写入, 磁盘IO大约100MB/s
- https://github.com/facebook/rocksdb/issues/182 发现100G基础数据时, 写1K的value性能也比较差.
- Hbase也有这个问题 http://www.infoq.com/cn/articles/hbase-casestudy-facebook-messages: Compaction操作就是读取小的HFile到内存merge-sorting成大的HFile然后输出,加速HBase读操作。Compaction操作导致写被放大17倍以上,
不过HBase社区很少关注这个问题.
猜测原因可能是HBase是一种批处理思路, 数据都是批量写入进去, 写进去后再一次性做一个Compaction.
4.3. 其它问题
这几个问题只针对LevelDB, RocksDB已经解决了:
每个mmtable太小(2M), 存在如下问题:
如果写入200G数据, 在db目录下就会有20w个文件, 需要频繁打开/关闭文件, 一个目录里面20w个文件的性能会很差(当然btrfs之类好些)对于50K的value, 一个文件只能放40个key-value对, 效率很低
Write Ahead Log 不能禁掉.
对于大value来说, 一个写请求, leveldb会写2份, write-ahead-log和真实数据, 浪费.
不能自定义compaction函数, 如果可以自定义, 则可以在compaction的时候做ttl功能.
compaction不能限速.
读触发compaction (allowed_seeks), 在某些场景不合适.
4.4. 小结
- leveldb 适用于小的kv库(value小(<1K), 总size小(<100G)), 比如chrome客户端 或者小的cache(比如某些模块自带的cache)
- 由于LevelDB把key和value都放在同一个文件里面, compaction的时候必须key和value一起读写, 所以写放大显得更为明显. 其实我们只需要保证key有序, compaction只需对key做就行了,key和value分开来存放也许一个不错的优化思路.
- 在程序里面, 可以把leveldb/rocksdb当做一个 自动扩容, 持久化 的hash表来用.